deployer组件的使用
deployer组件也就是canal-server,它负责管理维护多个instance,每个instance可以视为follower数据库,也就是说一个canal-server支持同步多个MySQL数据库实例数据。
1. 下载canal
访问release页面,下载已经编译好的压缩包。 
2. 上传服务器并解压文件
[jack@hadoop102 software]$ mkdir /opt/module/canal.deployer
[jack@hadoop102 software]$ tar -xvf canal.deployer-1.1.7.tar.gz -C /opt/module/canal.deployer
## 进入canal.deployer目录,可以看到如下结构
[jack@hadoop102 module]$ cd canal.deployer/
[jack@hadoop102 canal.deployer]$ ll
总用量 4
drwxrwxr-x. 2 jack jack 76 4月 23 21:53 bin
drwxrwxr-x. 5 jack jack 123 4月 23 21:53 conf
drwxrwxr-x. 2 jack jack 4096 4月 23 21:53 lib
drwxrwxr-x. 2 jack jack 6 10月 13 2023 logs
drwxrwxr-x. 2 jack jack 235 10月 13 2023 plugin3. 配置MySQL开启Binlog
3.1 配置my.cnf
# 开启binlog
log-bin=mysql-bin
# 选择ROW模式
binlog-format=ROW
# 指定开启binlog的数据库
binlog-do-db=demo
binlog-do-db=test重要提示
binlog-do-db根据自己的情况进行修改,指定具体要同步的数据库,如果不配置则表示所有数据库均开启binlog。
3.2 重启数据库并验证
- 重启数据库
[jack@hadoop105 module]$ sudo systemctl restart mysql
[jack@hadoop105 module]$ sudo systemctl status mysql
● mysql.service - MySQL server
Loaded: loaded (/usr/lib/systemd/system/mysql.service; disabled; vendor preset: disabled)
Active: active (running) since 二 2024-04-23 22:11:22 CST; 9s ago
Process: 109307 ExecStart=/opt/module/mysql-8.0.35/bin/mysqld --defaults-file=/etc/my.cnf --daemonize (code=exited, status=0/SUCCESS)
Main PID: 109311 (mysqld)
CGroup: /system.slice/mysql.service
└─109311 /opt/module/mysql-8.0.35/bin/mysqld --defaults-file=/etc/my.cnf --daemonize
4月 23 22:11:10 hadoop105 systemd[1]: Starting MySQL server...
4月 23 22:11:22 hadoop105 systemd[1]: Started MySQL server.- 验证配置生效
查询binlog状态,可以看到日志已经开启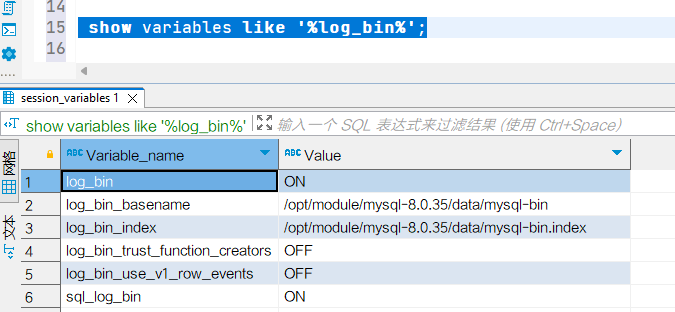 数据插入前,binlog日志如图所示:
数据插入前,binlog日志如图所示: 在数据库客户端中执行sql:
在数据库客户端中执行sql: 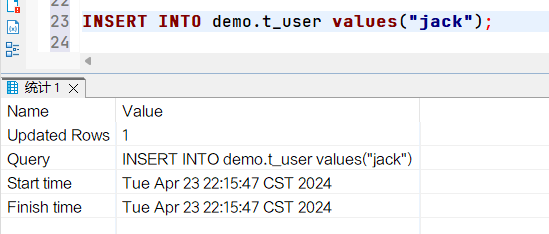 再次查看binlog日志,发现日志文件大小发生变化
再次查看binlog日志,发现日志文件大小发生变化
4. 提供canal数据库权限
CREATE USER canal IDENTIFIED BY 'canal';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
FLUSH PRIVILEGES;5. 配置canal.properties
canal.properties是canal的基本通用配置
[jack@hadoop102 conf]$ cat canal.properties
canal.port = 11111
# tcp, kafka, rocketMQ, rabbitMQ, pulsarMQ
canal.serverMode = tcp
canal.destinations = example
# conf root dir
canal.conf.dir = ../conf
canal.instance.global.mode = spring
canal.instance.global.lazy = false
# 设置canal-server记录位点的策略文件
canal.instance.global.spring.xml = classpath:spring/file-instance.xmlcanal.port配置deployer启动占用的端口号。canal.serverMode可以配置canal的解析数据库binlog日志输出的模式,默认为tcp,也就是直接输出到canal客户端中,canal也支持输出到MQ中,从而支持跨语言客户端进行消费处理。canal.destinations可以指定instance实例,一个canal服务中可以有多个instance, 默认提供example,多个实例名用逗号隔开,比如:canal.destinations=实例1,实例2,实例3。每个实例名是对应的配置文件夹的名称,每个文件夹下面必须含有一个instance.properties配置文件。canal.conf.dir配置conf文件夹的相对位置。canal.instance.global.mode配置读取instance方式:manager和spring; manager通过http请求读取admin的配置,spring通过配置文件的方式读取。canal.instance.global.lazy配置deployer启动时是否立即启动instance。canal.instance.global.spring.xml配置canal-server记录位点的策略,这里下一节进行详细介绍。
6. canal记录增量订阅&消费信息
canal.instance.global.spring.xml涉及到canal-server中两个位点信息维护:解析位点、消费位点
- 解析位点 (parse模块会记录,上一次解析binlog到了什么位置,对应类为:CanalLogPositionManager)
- 消费位点 (canal server在接收了客户端的ack后,就会记录客户端提交的最后位点,对应的类为:CanalMetaManager)
canal-server将这两个位点维护有下面三种策略实现(对应有三种不同的配置文件):
- memory:(memory-instance.xml配置文件)
所有的组件(parser , sink , store)都选择了内存版模式,记录位点的都选择了memory模式,重启后又会回到初始位点进行解析。
特点:速度最快,依赖最少(不需要zookeeper)。
场景:一般应用在quickstart,或者是出现问题后,进行数据分析的场景,不应该将其应用于生产环境。 - mixed: (file-instance.xml配置文件)
所有的组件(parser , sink , store)都选择了文件模式,记录位点的都选择了文件模式,重启后又会回到初始位点进行解析。
特点:位点持久化,重启后可以快速恢复。
场景:一般应用在小规模简单场景。 - zookeeper:(使用default-instance.xml配置文件)
store选择了内存模式,其余的parser/sink依赖的位点管理选择了持久化模式,目前持久化的方式主要是写入zookeeper,保证数据集群共享。
特点:支持HA。
场景:生产环境,集群化部署。 - group:(group-instance.xml配置文件) 主要针对需要进行多库合并时,可以将多个物理instance合并为一个逻辑instance,提供客户端访问。 场景:分库业务。 比如产品数据拆分了4个库,每个库会有一个instance,如果不用group,业务上要消费数据时,需要启动4个客户端,分别链接4个instance实例。使用group后,可以在canal server上合并为一个逻辑instance,只需要启动1个客户端,链接这个逻辑instance即可.
7. 配置instance.properties
若读取一个MySQL服务器数据,可以只用一个instance实例,instance实例需要命名,默认canal配置名称为example,它的instance的配置文件就在conf/example目录下。
[jack@hadoop102 conf]$ cd example/
[jack@hadoop102 example]$ ll
总用量 4
-rwxrwxr-x. 1 jack jack 2224 4月 21 2023 instance.propertiesinstance.properties配置信息如下
# 1.配置fllower的id,不能和源数据库id冲突
canal.instance.mysql.slaveId=123
# 2. 配置基于GTID位点的数据订阅,前提需要源数据库开启GTID模式
canal.instance.gtidon=false
# 3. 配置源MySQL服务器地址
canal.instance.master.address=192.168.101.105:3306
# 4. 配置连接MySQL的用户名和密码,默认就是我们前面授权的canal
canal.instance.dbUsername=canal
canal.instance.dbPassword=canal
# 5. 是否密码需要解密
canal.instance.enableDruid=false
# 6. 配置字符编码
canal.instance.connectionCharset = UTF-8
# 7. 配置那些表同步
canal.instance.filter.regex=.*\\..*
# 8. 配置不同步那些表
canal.instance.filter.black.regex=mysql\\.slave_.*
# 用来配置MySQL从节点数据库地址,以防MySQL主节点数据库挂了,不能读取binglog日志
#canal.instance.standby.address =
#canal.instance.standby.journal.name =
#canal.instance.standby.position =
#canal.instance.standby.timestamp =
#canal.instance.standby.gtid=提示
- 如果系统是1个cpu,需要将canal.instance.parser.parallel设置为false。
canal.instance.mysql.slaveId:mysql集群配置中的serverId概念,需要保证和当前mysql集群中id唯一,v1.1.x版本之后canal会自动生成,不需要手工指定。canal.instance.filter.regex和canal.instance.filter.black.regex: 分别表示需要解析的表和不解析的表,配置内容是Perl正则表达式组成的过滤条件,表达式只针对row格式的binlog数据有效,多个正则之间以逗号(,)分隔,转义符需要双斜杠(\) ,常见例子:- 所有表:.* or .\..
- canal schema下所有表: canal\..*
- canal下的以canal打头的表:canal\.canal.*
- canal schema下的一张表:canal.test1
- 多个规则组合使用:canal\..*,mysql.test1,mysql.test2 (逗号分隔)
canal.instance.standby.xxx: 目前本地MySQL数据库为单节点, 无需配置。
8. 启动canal和example实例
[jack@hadoop102 canal.deployer]$ sh bin/startup.sh查看server日志
[jack@hadoop102 canal.deployer]$ cat logs/canal/canal.log
2024-04-23 22:58:48.458 [main] INFO com.alibaba.otter.canal.deployer.CanalLauncher - ## set default uncaught exception handler
2024-04-23 22:58:48.480 [main] INFO com.alibaba.otter.canal.deployer.CanalLauncher - ## load canal configurations
2024-04-23 22:58:48.496 [main] INFO com.alibaba.otter.canal.deployer.CanalStarter - ## start the canal server.
2024-04-23 22:58:48.601 [main] INFO com.alibaba.otter.canal.deployer.CanalController - ## start the canal server[172.17.0.1(172.17.0.1):11111]
2024-04-23 22:58:51.932 [main] INFO com.alibaba.otter.canal.deployer.CanalStarter - ## the canal server is running now ......查看example实例的日志
[jack@hadoop102 canal.deployer]$ cat logs/example/example.log
2024-04-23 22:58:50.008 [main] INFO c.a.otter.canal.instance.spring.CanalInstanceWithSpring - start CannalInstance for 1-example
2024-04-23 22:58:51.843 [main] WARN c.a.o.canal.parse.inbound.mysql.dbsync.LogEventConvert - --> init table filter : ^.*\..*$
2024-04-23 22:58:51.843 [main] WARN c.a.o.canal.parse.inbound.mysql.dbsync.LogEventConvert - --> init table black filter : ^mysql\.slave_.*$
2024-04-23 22:58:51.849 [main] INFO c.a.otter.canal.instance.core.AbstractCanalInstance - start successful....
2024-04-23 22:58:52.645 [destination = example , address = /192.168.101.105:3306 , EventParser] WARN c.a.o.c.p.inbound.mysql.rds.RdsBinlogEventParserProxy - ---> begin to find start position, it will be long time for reset or first position
2024-04-23 22:58:52.645 [destination = example , address = /192.168.101.105:3306 , EventParser] WARN c.a.o.c.p.inbound.mysql.rds.RdsBinlogEventParserProxy - prepare to find start position just show master status
2024-04-23 22:58:57.179 [destination = example , address = /192.168.101.105:3306 , EventParser] WARN c.a.o.c.p.inbound.mysql.rds.RdsBinlogEventParserProxy - ---> find start position successfully, EntryPosition[included=false,journalName=mysql-bin.000001,position=609,serverId=1,gtid=,timestamp=1713881919000] cost : 4502ms , the next step is binlog dump至此canal-server监听192.168.101.105数据库实例配置并启动完成。