Paimon性能优化
1. 写入性能
Paimon的写入性能与检查点密切相关,因此需要更大的写入吞吐量:
- 增加检查点间隔,或者仅使用批处理模式。
- 增加写入缓冲区大小(
write-buffer-size)。 - 启用写缓冲区溢出(
write-buffer-spillable)。 - 如果您使用固定存储桶模式,请重新调整存储桶数量。
2.并行度
建议sink的并行度小于等于bucket的数量,最好相等。
| 选项 | 必需的 | 默认 | 类型 | 描述 |
|---|---|---|---|---|
sink.parallelism | No | (none) | Integer | 定义sink的并行度。默认情况下, 并行度由框架使用上游链式运算符的相同并行度来确定。 |
3. 压缩
3.1 避免写入暂停
Sorted Run数量比较少时,Paimon writer可以执行异步压缩, 从而不影响数据的连续写入。但Sorted Runs如果太多,Sorted Run的数量达到阈值时,writer将暂停写入数据。配置Sorted Run的阈值:
| 选项 | 必需的 | 默认 | 类型 | 描述 |
|---|---|---|---|---|
num-sorted-run.stop-trigger | No | (none) | Integer | 触发停止写入的Sorted Runs次数, 默认值为 num-sorted-run.compaction-trigger+ 1。 |
当num-sorted-run.stop-trigger较大时,写入停顿将变得不那么频繁,从而提高写入性能。但如果参数设置太大,会导致查询变慢甚至是OOM, 进一步可以设置sort-spill-threshold参数(限制查询的内存大小)。
3.2 文件压缩
Paimon默认使用zstd格式,压缩等级为1,最高为9,调节参数为file.compression.zstd-level。
4. 本地合并
如果你的作业存在主键数据倾斜,可以设置local-merge-buffer-size,以便在写入sink之前通过bucket进行shuffle被缓冲和合并。缓冲区会在满时被刷新。建议最小缓冲区大小为64M。
5. 提高写入吞吐量
如果希望Paimon具有最大写入吞吐量,则可以缓慢而不是匆忙地进行压缩。可以对表使用以下策略:
num-sorted-run.stop-trigger = 2147483647
sort-spill-threshold = 106. 合并Sorted Run数阈值
过多的Sorted Run会导致查询性能不佳。为了将Sorted Run的数量保持在合理的范围内,Paimon writer将自动执行Compaction从而减少Sorted Run数。下表属性确定触发Compaction的最小Sorted Run数。
| 选项 | 必需的 | 默认 | 类型 | 描述 |
|---|---|---|---|---|
num-sorted-run.compaction-trigger | No | 5 | Integer | 触发Compaction的Sorted Run数。 包括0级文件(一个文件一级排序运行)和高级运行(一个一级排序运行) |
7. 写入初始化
在write初始化时,bucket的writer需要读取所有历史文件。如果这里出现瓶颈(例如同时写入大量分区),可以使用write-manifest-cache缓存读取的manifest数据,以加速初始化。
8. 文件格式
如果想要达到极致的压缩性能,可以考虑使用行存储文件格式AVRO。优点是可以实现高写入吞吐量和压缩性能。缺点是你的分析查询会很慢,通过以下选项启用存储格式:
file.format = avro
metadata.stats-mode = nonePaimon对parquet读取进行了一些查询优化,因此parquet会比orc稍快一些。其中avro是行存储,parquet和orc都是列存储。
9. 提高稳定性
压缩等级太高可能导致检查点超时,默认Flink的检查点超时为10分钟,就需要调高检查点超时:
execution.checkpointing.timeout = 60 min10. 写入初始化
在write初始化时,bucket的writer需要读取所有历史文件。如果这里出现瓶颈(例如同时写入大量分区),可以使用write-manifest-cache缓存读取的manifest数据,以加速初始化。
11. 尽量使用主键表
主键表在查询时使用主键查询性能更好,主键表在Paimon中默认为Merge On Read(简称MOR)表,
Merge On Read、Copy On Write和Merge On Write区别
- Merge On Read指的是读取数据需要进行合并文件操作,并且所有文件合并会存在不同的Sortd Run文件有相同主键的数据,会有取舍,丢弃老的相同主键数据。由于在Paimon中单个LSM树只能有一个线程读取,但如果存储桶中的数据量过大,会导致读取性能不佳。推荐设置Bucket中的数据量设置为在200MB 到1GB之间。因此写入性能:非常好。读取性能:不太好。
- Copy On Write:开启需要设置表'full-compaction.delta-commits' = '1',也就是每次写入都会复制一份完整的mainfest文件,在新的复制文件中进行合并,保留了历史版本。读取时不需要合并,读取性能很高。因此写入性能:很差。读取性能:非常好。
- Merge On Write: 对于主键表,开启需要设置表'deletion-vectors.enabled' = 'true',在写入数据的时候会触发合并操作,会生成删除相同主键旧数据的向量指令文件,这些向量指令文件执行非常高效,相当于只保留了最新版本的数据文件。因此写入性能:一般。读取性能:很好。
如果你想在某些场景下查询较旧的数据比较快,可以如下优化:
- 配置
full-compaction.delta-commits,写入数据时(目前只有Flink)会定期进行full Compaction。 - 配置
scan.mode”为“compacted-full,读取数据时,选择full-compaction的快照。读取性能良好。
12. 内存优化
Paimon writer中主要占用内存的地方有3个:
- Writer的内存缓冲区,由单个任务的所有Writer共享和抢占。该内存值可以通过
write-buffer-size表属性进行调整。 - 合并多个Sorted Run以进行Compaction时会消耗内存。可以通过
num-sorted-run.compaction-trigger选项进行调整,以更改要合并的Sorted Run的数量。 - 如果行非常大,在进行Compaction时一次读取太多行数据可能会消耗大量内存。减少
read.batch-size选项可以减轻这种情况的影响。 - 写入列式(ORC、Parquet等)文件所消耗的内存,不可调。
13. 多Writer并发写入
Paimon的快照管理支持向多个writer写入。默认情况下,Paimon支持对不同分区的并发写入。推荐的方式是streaming job将记录写入Paimon的最新分区;同时批处理作业(覆盖)将记录写入历史分区。 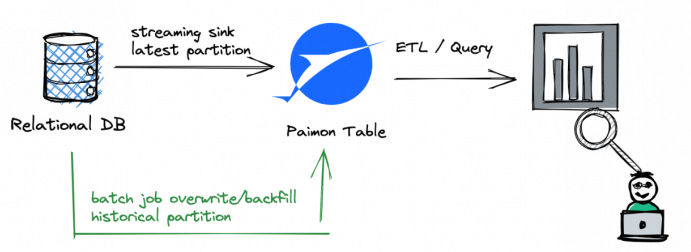 如果需要多个Writer写到同一个分区,事情就会变得有点复杂。例如不想使用UNION ALL,那就需要有多个流作业来写入partial-update表。所谓partial-update表就是多个writer可以直接写入同一个分区,相同主键的数据会被写后合并。
如果需要多个Writer写到同一个分区,事情就会变得有点复杂。例如不想使用UNION ALL,那就需要有多个流作业来写入partial-update表。所谓partial-update表就是多个writer可以直接写入同一个分区,相同主键的数据会被写后合并。
14. 合并Job
默认情况下,Paimon writer 在写入记录时会根据需要执行Compaction。但有两个缺点:
- 这可能会导致写入吞吐量不稳定,因为执行压缩时吞吐量可能会暂时下降。
- Compaction会将某些数据文件标记为“已删除”(并未真正删除)。如果多个writer标记同一个文件,则在提交更改时会发生冲突。 Paimon 会自动解决冲突,但这可能会导致作业重新启动。
为了避免这些缺点,用户还可以选择在writer中跳过Compaction,并仅运行专门的作业来进行Compaction。由于Compaction仅由专用作业执行,因此writer可以连续写入记录而无需暂停,并且不会发生冲突。
| 选项 | 必需 | 默认 | 类型 | 描述 |
|---|---|---|---|---|
| write-only | No | false | Boolean | 如果设置为 true,将跳过Compaction和快照过期。 此选项与独立Compaction一起使用。 |
Flink SQL目前不支持compaction相关的语句,所以我们必须通过flink run来提交compaction作业。
<FLINK_HOME>/bin/flink run \
/path/to/paimon-flink-action-0.5-SNAPSHOT.jar \
compact \
--warehouse <warehouse-path> \
--database <database-name> \
--table <table-name> \
[--partition <partition-name>] \
[--catalog-conf <paimon-catalog-conf> [--catalog-conf <paimon-catalog-conf> ...]] \如果提交一个批处理作业(execution.runtime-mode:batch),当前所有的表文件都会被Compaction。如果您提交一个流作业(execution.runtime-mode: streaming),该作业将持续监视表的新更改并根据需要执行Compaction。