Paimon入门
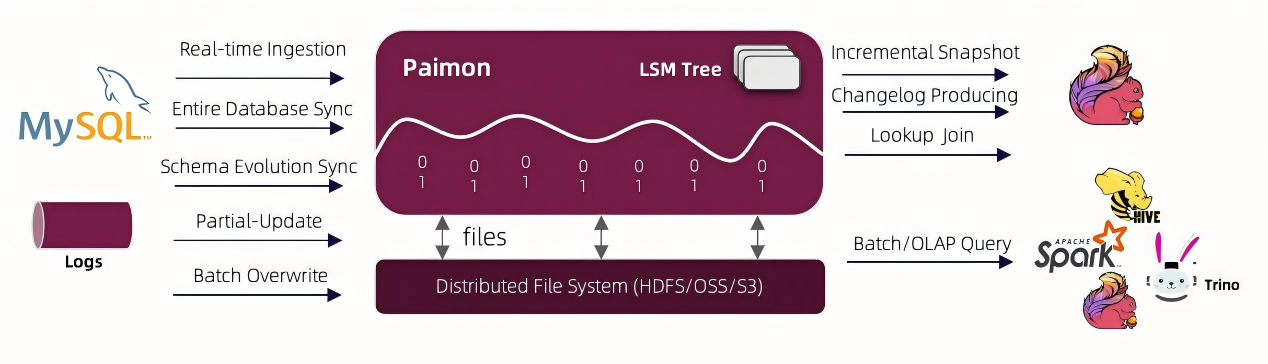 可以看到Paimon在图中支持实时集成和整库同步、表结构变更同步、部分列更新、批量的覆盖,Paimon居中有呈现有波浪的数据湖。数据结构采用LSM Tree,比如HBase、ClickHouse也是采用LSM Tree, 输出方便支持增量的快照、Changelog的生成以及伪表Join, 对数据的OLAP查询。
可以看到Paimon在图中支持实时集成和整库同步、表结构变更同步、部分列更新、批量的覆盖,Paimon居中有呈现有波浪的数据湖。数据结构采用LSM Tree,比如HBase、ClickHouse也是采用LSM Tree, 输出方便支持增量的快照、Changelog的生成以及伪表Join, 对数据的OLAP查询。
1. 简介
Apache Paimon是一个流数据湖平台,Flink社区内部孵化了Flink Table Store(简称FTS)子项目,一个真正面向Streaming以及Realtime的数据湖存储项目。2023年3月12日,FTS进入Apache软件基金会 (ASF)的孵化器,改名为Apache Paimon。
2. 核心特性
- 统一批处理和流处理
批量写入和读取、流式更新、变更日志生成,全部支持。 - 数据湖能力
低成本、高可靠性、可扩展的元数据。 Apache Paimon 具有作为数据湖存储的所有优势。 - 各种合并引擎
按照您喜欢的方式更新记录。保留最后一条记录、进行部分更新或将记录聚合在一起,由您决定。 - 变更日志生成
Apache Paimon 可以从任何数据源生成正确且完整的变更日志,从而简化您的流分析。 - 丰富的表类型
除了主键表之外,Apache Paimon还支持append-only表,提供有序的流式读取来替代消息队列。 - 模式变更
Paimon支持完整的模式变更。您可以重命名列并重新排序。
3. 基本概念
3.1 文件存储设计
一个表的所有文件都存储在一个基础目录下。Paimon文件采用分层方式组织。下图展示了文件存储的详情。从一个快照文件开始,Paimon读取器可以递归访问表中的所有记录。 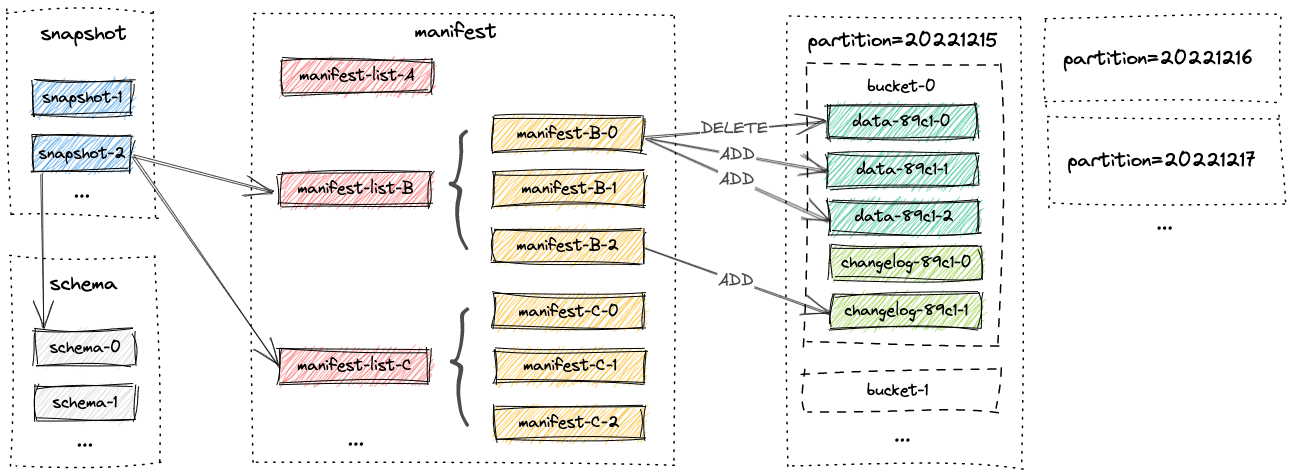
3.2 Snapshot
快照可捕获表在某个时间点的状态。用户可以通过最新的快照访问表的最新数据。通过时间回溯,用户还可以通过更早的快照访问表的先前状态。Snapshot是一个JSON文件,里面包含schema文件、manifest列表。
3.3 Manifest文件
manifest包含了清单列表和清单文件,清单列表(manifest list)是清单文件名(manifest file)的列表。清单文件(manifest file)是包含有关 LSM 数据文件和更改日志文件的文件信息。例如对应快照中创建了哪个LSM数据文件、删除了哪个文件。
3.4 Data文件
数据文件按分区进行分组。Paimon支持使用Parquet(默认)、Orc和Avro作为数据文件格式。
3.5 分区分桶
和Hive类似,如果定义了主键,则分区键必须是主键的子集。未分区表或分区表中的分区被细分为存储桶,桶是读写的最小存储单元,因此桶的数量限制了最大处理并行度。
3.6 LSM Trees
Paimon采用LSM树(Log-Structured Merge Tree)日志结构合并树作为文件存储的数据结构。 LSM树是一种面向写密集场景设计的存储索引结构, 广泛应用于LevelDB、RocksDB、HBase、Cassandra等主流存储系统中。相比于传统数据库常用B+树作为索引结构,其优势是读性能高效, 但在写密集场景(如高频插入、更新)中存在明显瓶颈:
- 随机写开销大:B+ 树为保证有序性,插入 / 更新时需找到对应叶子节点位置,若节点已满还需触发 “分裂 / 合并”,导致大量磁盘随机 I/O(磁盘随机读写速度远低于顺序读写);
- 写放大问题:一次数据更新可能引发多级节点的修改(如叶子节点→父节点→根节点),实际写入磁盘的数据量远大于用户提交的数据量。
为解决上述问题,LSM树通过"将随机写转化为顺序写"的设计, LSM树的存储结构分为内存层(MemTable)和磁盘层(SSTable)两大部分, 整体遵循"先写内存、再异步刷盘、定期合并"的流程。
3.6.1 Sorted Runs
LSM树将文件组织成多个Sorted Run。Sorted Run由一个或多个数据文件组成,并且每个数据文件恰好属于一个Sorted Run。数据文件中的记录按其主键排序。在Sorted Run中,数据文件的主键范围永远不会重叠。但是不同的Sorted Run可能具有重叠的主键范围。查询LSM树时会合并所有的Sorted Run,这时需要合并相同主键的不同Sorted Run的数据。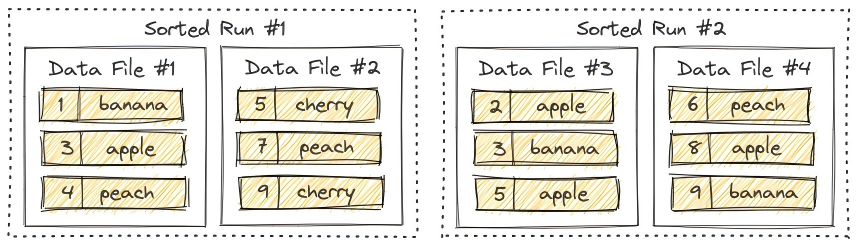 写入LSM树的新记录将首先缓存在内存中。当内存缓冲区满时,内存中的所有记录将被排序并刷新到磁盘。
写入LSM树的新记录将首先缓存在内存中。当内存缓冲区满时,内存中的所有记录将被排序并刷新到磁盘。
3.6.2 Compaction
由于查询LSM树需要将所有Sorted Run合并起来,太多Sorted Run将导致查询性能较差,甚至内存不足,为了限制Sorted Run的数量,我们必须定期将多个Sorted Run合并为一个大的Sorted Run。这个过程称为Compaction。合并频率目前采用了类似于Rocksdb通用压缩的Compaction策略, 默认情况下,当Paimon将记录追加到LSM树时,它也会根据需要执行Compaction。用户还可以选择在"专用Compaction作业"中独立执行所有Compaction。
提示
Compaction是一个资源密集型任务过程,会消耗一定的CPU时间和磁盘IO,因此过于频繁的Compaction可能会导致写入速度变慢。这是查询和写入性能之间的权衡。