集成Flink
1. 版本选择
Paimon目前支持Flink1.15~20,我们使用Flink1.16.2
2. 环境准备
2.1 安装Flink
请参考Flink部署模式
2.2 上传Paimon包
- jar包下载地址:https://paimon.apache.org/docs/0.8/project/download/ ,选择Flink16的版本:
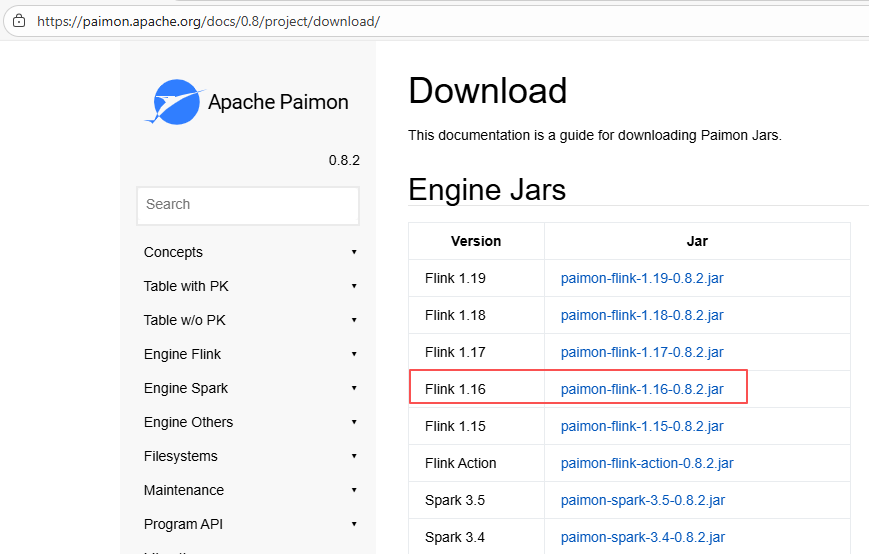
- 拷贝paimon的jar包到flink的lib目录下:
cp paimon-flink-1.16-0.8.2.jar /opt/gbaseHD/flink-1.16.2/lib2.3 启动sql-client
- 修改flink-conf.yaml配置
vim /opt/gbaseHD/flink-1.16.2/conf/flink-conf.yaml
# 解决中文乱码,1.17之后参数是env.java.opts.all
env.java.opts: -Dfile.encoding=UTF-8
classloader.check-leaked-classloader: false
taskmanager.numberOfTaskSlots: 4
execution.checkpointing.interval: 10s
state.backend: rocksdb
state.checkpoints.dir: hdfs://hadoop102:8020/ckps
state.backend.incremental: true- 解决依赖问题
cp /opt/gbaseHD/hadoop-3.3.3/share/hadoop/mapreduce/hadoop-mapreduce-client-core-3.3.3.jar /opt/gbaseHD/flink-1.16.2/lib/- 以Yarn-Session模式启动
## 开启yarn-session模式,执行过程稍微等一下会自动完成退出
/opt/gbaseHD/flink-1.16.2/bin/yarn-session.sh -nm test -d
## 启动Flink的sql-client
/opt/gbaseHD/flink-1.16.2/bin/sql-client.sh -s yarn-session 4. 设置结果显示模式
4. 设置结果显示模式
SET 'sql-client.execution.result-mode' = 'tableau';
SET 'rest.address' = 'gbasehd113';
SET 'rest.port' = '38381';如果执行任务报错:
Flink SQL> select 1;
[ERROR] Could not execute SQL statement. Reason:
java.lang.NullPointerException: rest.address must be set可以设置两个属性:
Flink SQL> SET 'rest.address' = 'gbasehd113';
Flink SQL> SET 'rest.port' = '38381';3. Catalog
Paimon提供了Catalog抽象概念来管理表数据和元数据,Paimon目前支持四种类型的元存储:
- filesystemmetastore(默认),将元数据和表文件存储在文件系统中。
- hivemetastore,它还将元数据存储在Hive元存储中。用户可以直接从Hive访问表。
- jdbcmetastore,它额外将元数据存储在关系数据库中,例如MySQL、Postgres等。
- restmetastore,旨在提供一种从单个客户端访问任何目录后端的轻量级方式。
3.1 Filesystem Catalog
CREATE CATALOG fs_catalog WITH (
'type' = 'paimon',
'warehouse' = 'hdfs://Node01:8020/paimon/warehouse'
);
## 如果想创建外部表的Catalog, Paimon不支持filesystem类型:
-- table.type属性为external
CREATE CATALOG external_catalog_fs WITH (
'type'='paimon',
'warehouse'='hdfs://Node01:8020/paimon/external/fs',
'table.type' = 'external'
);执行报错:  在不指定table.type' = 'external'属性的catalog中,需要指定说明conetcor表属性创建外部表,查看当前所有的catalog:
在不指定table.type' = 'external'属性的catalog中,需要指定说明conetcor表属性创建外部表,查看当前所有的catalog:
Flink SQL> show catalogs;
+-----------------+
| catalog name |
+-----------------+
| default_catalog |
| fs_catalog |
+-----------------+
2 rows in set在HDFS的页面上,可以发现默认会创建一个default的数据库: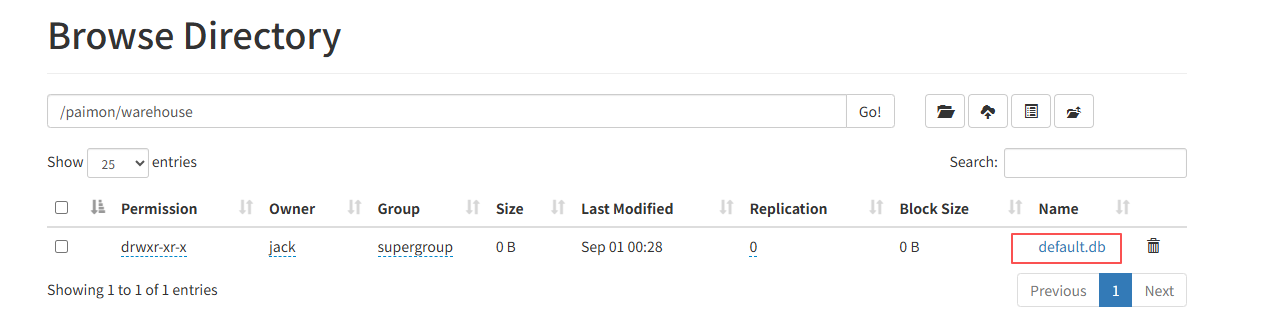
3.2 Hive Catalog
通过使用Hive Catalog,对Catalog的更改将直接影响相应的hive metastore。在此类Catalog中创建的表也可以直接从Hive访问。要使用Hive Catalog,数据库名称、表名称和字段名称应小写。
- 上传hive-connector
由于要连接hive的metastore服务,需要使用hive的连接器,以及需要提前启动metastore服务。访问Flink官网的Hive连接器章节,将flink-sql-connector-hive-3.1.3_2.12-1.16.2.jar下载后上传到Flink的lib目录下即可。 - 重启yarn-session集群
由于新添加了jar包,重启yarn-session生效。同时sql-client也要重启。 - 创建catalog
create catalog hive_catalog with (
'type'='paimon',
'metastore'='hive',
'uri'='thrift://Node02:9083',
'hive-conf-dir' = '/opt/module/hive-4.1.0/conf',
-- 一定要按照真实hive仓库地址,自定义warehouse会被覆盖
'warehouse'='hdfs://Node01:8020/user/hive/warehouse'
);
-- 创建支持外部表的catalog
CREATE CATALOG external_catalog_hive WITH (
'type'='paimon',
'metastore' = 'hive',
'uri' = 'thrift://192.168.7.113:9083',
'warehouse'='hdfs://Node01/user/hive/warehouse',
'table.type' = 'external'
);自定义warehouse地址会无效,因为Paimon会读取hive-conf-dir的配置文件内容。
3.3 JDBC Catalog
通过JDBC方式将传统RDMS上的数据库纳入到Paimon的管理,需要提前把数据库驱动包放到Flink的lib目录下。
- 将MySQL的驱动包放到lib目录
[jack@Node02 software]$ cp mysql-connector-j-8.0.33.jar /opt/module/flink-1.20.2/lib/- 重启yarn-session集群
由于新添加了jar包,重启yarn-session生效。同时sql-client也要重启。 - 创建catalog
CREATE CATALOG mysql_catalog WITH (
'type' = 'paimon',
'metastore' = 'jdbc',
'uri' = 'jdbc:mysql://Node03:3306/dm',
'jdbc.user' = 'root',
'jdbc.password' = '123456',
'catalog-key'='jdbc',
'warehouse' = 'hdfs://Node01:8020/mysql/warehouse'
);查看mysql_catalog中的表,发现Paimon并不会主动管理MySQL上已有的表:
Flink SQL> use catalog mysql_catalog;
[INFO] Execute statement succeeded.
Flink SQL> show tables;
Empty set3.4 REST Catalog
4. sql初始化文件
每次关闭sql-clinet,会发现再次启动后之前的catalog和数据库、表都不在了,并非真正的被删除了而是表信息没有持久化保存,可以创建sql-client的初始化文件,再启动之前加载我们要使用的catalog。
4.1 创建初始化sql文件
vim sql-client-init.sql
## 添加的内容如下
CREATE CATALOG fs_catalog WITH (
'type' = 'paimon',
'warehouse' = 'hdfs://Node01:8020/paimon/warehouse'
);
create catalog hive_catalog with (
'type'='paimon',
'metastore'='hive',
'uri'='thrift://Node02:9083',
'hive-conf-dir' = '/opt/module/hive-4.1.0/conf',
'warehouse'='hdfs://Node01:8020/user/hive/warehouse'
);
USE CATALOG hive_catalog;
SET 'sql-client.execution.result-mode' = 'tableau';4.2 启动sql-client
./sql-client.sh -s yarn-session -i sql-client-init.sql4.3 查看Catalog
show catalogs;
show current catalog;5. 建表
在Paimon Catalog中创建的表就是Paimon的管理表。当表从Catalog中删除时,默认其表文件也将被删除,类似于Hive的内部表。若需创建外部表,需要创建外部表的Catalog, 在Paimon Catalog中建表只能创建paimon格式的表,不支持除了paimon之外其他connector,也就是不能指明外部表。
5.1 创建普通表
CREATE TABLE t_test (
user_id BIGINT,
item_id BIGINT,
behavior STRING,
dt STRING,
hh STRING,
PRIMARY KEY (dt, hh, user_id) NOT ENFORCED
);5.2 查看表结构
查看创建好的表:
Flink SQL> desc t_test;
+----------+--------+-------+----------------------+--------+-----------+
| name | type | null | key | extras | watermark |
+----------+--------+-------+----------------------+--------+-----------+
| user_id | BIGINT | FALSE | PRI(dt, hh, user_id) | | |
| item_id | BIGINT | TRUE | | | |
| behavior | STRING | TRUE | | | |
| dt | STRING | FALSE | PRI(dt, hh, user_id) | | |
| hh | STRING | FALSE | PRI(dt, hh, user_id) | | |
+----------+--------+-------+----------------------+--------+-----------+
5 rows in set查看建表信息:
Flink SQL> show create t_test
CREATE TABLE t_test (
user_id BIGINT,
item_id BIGINT,
behavior STRING,
dt STRING,
hh STRING,
PRIMARY KEY (dt, hh, user_id) NOT ENFORCED
);5.3 创建分区表
如果定义了主键,则分区字段必须是主键的子集。通过配置partition.expiration-time表属性,可以自动删除过期的分区。
CREATE TABLE t_test_p (
user_id BIGINT,
item_id BIGINT,
behavior STRING,
dt STRING,
hh STRING,
PRIMARY KEY (dt, hh, user_id) NOT ENFORCED
) PARTITIONED BY (dt, hh);常见的,一般会考虑定义以下三类字段为分区字段:
- 创建时间字段(推荐):创建时间通常是不可变的,因此您可以放心地将其视为分区字段并将其添加到主键中。
- 事件时间字段:事件时间是原表中的一个字段(比如updated_time)。对于CDC数据来说,比如从MySQL CDC同步的表或者Paimon生成的Changelogs。它们都是完整的CDC数据,包括了UPDATE_BEFORE记录,从而Paimon可以自动删除之前老分区的数据。
- CDC工具提供的op_ts字段:不推荐定义为分区字段,无法知道之前的记录时间戳。
5.4 CTAS建表
Paimon表可以通过查询的结果创建和填充:
CREATE TABLE test1(
user_id BIGINT,
item_id BIGINT
);
CREATE TABLE test2 AS SELECT * FROM test1;通过CTAS建表可以重新指定主键等信息。
-- 指定分区
CREATE TABLE test2_p WITH ('partition' = 'dt') AS SELECT * FROM test_p;
-- 指定格式配置
CREATE TABLE test3(
user_id BIGINT,
item_id BIGINT
) WITH ('file.format' = 'orc');
CREATE TABLE test3_op WITH ('file.format' = 'parquet') AS SELECT * FROM test3;
-- 指定主键
CREATE TABLE test_pk WITH ('primary-key' = 'dt,hh') AS SELECT * FROM test;
-- 指定主键和分区
CREATE TABLE test_all WITH ('primary-key' = 'dt,hh', 'partition' = 'dt') AS SELECT * FROM test_p;5.5 CTL建表
创建与另一个表具有相同schema、分区和表属性的表,但不包含数据。
CREATE TABLE test_ctl LIKE test;5.6 表属性
表的属性有很多,具体请参阅配置,通过with指定属性:
CREATE TABLE tbl(
user_id BIGINT,
item_id BIGINT,
behavior STRING,
dt STRING,
hh STRING,
PRIMARY KEY (dt, hh, user_id) NOT ENFORCED
) PARTITIONED BY (dt, hh)
WITH (
'bucket' = '2',
'bucket-key' = 'user_id'
);5.7 外部表
类似于Hive的外部表,Paimon的外部表被删除不会清除数据文件,Paimon的外部表可以在任何非Paimon类型的Catalog中使用,使用Paimon的外部表需要在建表的时候申明connector为paimon和path属性即可。
-- 在paimon的catalog中创建外部表,需要指明'auto-create'属性为false
create table t_fs_external(
id INT,
name string,
age INT
)
with (
'connector' = 'paimon',
'path' = 'hdfs://gbasehd111:8020/paimon/external/fs/t_fs_external',
'auto-create' = 'false'
);
--而在非Paimon的catalog中,建表没有限制外部表
create table tt(
id INT,
name string,
age INT
)
with (
'connector' = 'paimon',
'path' = 'hdfs://gbasehd111:8020/paimon/external/fs/tt',
'auto-create' = 'true'
);5.8 临时表
相对Spark\Hive, 只有Flink支持临时表。如果临时表被删除,其资源将不会被删除,Flink SQL会话关闭时,临时表也会被删除。再次创建Catalog后临时表不像外部表还能找到,与外部表的区别在于,临时表在Paimon Catalog中创建。
CREATE TEMPORARY TABLE t_temp (
k INT,
v STRING
) WITH (
'connector' = 'filesystem',
'path' = 'hdfs://hadoop102:8020/temp.csv',
'format' = 'csv'
);6. 修改表
6.1 更改/添加表属性
ALTER TABLE test SET (
'write-buffer-size' = '256 MB'
);6.2 重命名表
ALTER TABLE test1 RENAME TO test_new;6.3 删除表属性
ALTER TABLE test RESET ('write-buffer-size');6.4 添加新列
ALTER TABLE test ADD (c1 INT, c2 STRING);6.5 重命名列
ALTER TABLE test RENAME c1 TO c0;6.6 删除列
ALTER TABLE test DROP (c0, c2);6.7 更改列的可为空
CREATE TABLE test_null(
id INT PRIMARY KEY NOT ENFORCED,
coupon_info FLOAT NOT NULL
);
-- 列coupon_info修改成允许为null
ALTER TABLE test_null MODIFY coupon_info FLOAT;
-- 列coupon_info修改成不允许为null
-- 如果表中已经有null值, 修改之前先设置如下参数删除null值
SET 'table.exec.sink.not-null-enforcer' = 'DROP';
ALTER TABLE test_null MODIFY coupon_info FLOAT NOT NULL;6.8 更改列注释
ALTER TABLE test MODIFY user_id BIGINT COMMENT 'user id';6.9 更改列位置
ALTER TABLE test MODIFY b INT FIRST;
ALTER TABLE test MODIFY a INT AFTER user_id;6.10 更改列类型
ALTER TABLE test MODIFY a DOUBLE;6.11 添加水印
CREATE TABLE test_wm (
id INT,
name STRING,
ts BIGINT
);
ALTER TABLE test_wm ADD(
et AS to_timestamp_ltz(ts,3),
WATERMARK FOR et AS et - INTERVAL '1' SECOND
);6.12 更改水印
ALTER TABLE test_wm MODIFY WATERMARK FOR et AS et - INTERVAL '2' SECOND;6.12 删除水印
ALTER TABLE test_wm DROP WATERMARK;7. DDL
7.1 插入数据
INSERT语句向表中插入新行或覆盖表中的现有数据。sql语法如下:
INSERT { INTO | OVERWRITE } table_identifier [ part_spec ] [ column_list ] { value_expr | query }其中:
- part_spec:可选,指定分区的键值对列表,多个用逗号分隔。格式为PARTITION (分区列名称 = 分区列值 [ , … ] )
- column_list:可选,指定以逗号分隔的字段列表。
- value_expr:指定要插入的值。可以指定多于一组的值来插入多行。
目前,Flink 不支持直接使用NULL,因此需要将NULL转换为实际数据类型值,比如“CAST (NULL AS STRING)”再插入。也不能将另一个表的可为空列插入到一个表的非空列中。Flink可以使用COALESCE函数来处理:
INSERT INTO A key1 SELECT COALESCE(key2, <non-null expression>) FROM B7.2 插入有界数据
需要提前设置批模式:
SET 'execution.runtime-mode' = 'batch';
insert into user_info values (1, 'test', 123);7.3 插入无界数据
需要提前设置流模式(默认不改就是流模式):
-- 流模式
SET 'execution.checkpointing.interval' = '5s';
CREATE TABLE IF NOT EXISTS kafka_input (
id int,
name STRING,
age INT,
`offset` STRING METADATA VIRTUAL
)
WITH
(
'connector' = 'kafka',
'topic' = 'NewTopic',
'properties.bootstrap.servers' = 'gbasehd111:9092,gbasehd112:9092,gbasehd113:9092',
'properties.group.id' = 'test-group',
'scan.startup.mode' = 'earliest-offset',
'format' = 'json'
);
insert into user_source(id, name, age) select id, name, age from default_catalog.default_database.kafka_input;7.4 覆盖数据
覆盖数据只支持batch模式。默认情况下,流式读取将忽略INSERT OVERWRITE生成的提交。 
- 覆盖未分区的表
SET 'execution.runtime-mode' = 'batch';
--覆盖前数据
Flink SQL> select * from t_test_internal;
+----+--------+
| id | name |
+----+--------+
| 1 | <NULL> |
+----+--------+
1 row in set (19.70 seconds)
INSERT OVERWRITE t_fs_external VALUES(3, 'pay', 2);
-- 覆盖后数据,说明覆盖和Hive不一样,Paimon是全部覆盖,Hive是相关的覆盖
Flink SQL> select * from t_fs_external;
+----+------+-----+
| id | name | age |
+----+------+-----+
| 3 | pay | 2 |
+----+------+-----+
1 row in set- 覆盖分区表 对于分区表,Paimon默认的覆盖模式是动态分区覆盖(即Paimon只删除insert overwrite数据中出现的分区)
INSERT OVERWRITE test_p SELECT * from test;
-- 覆盖指定分区
INSERT OVERWRITE test_p PARTITION (dt = '2023-07-01', hh = '2') SELECT user_id,item_id,behavior from test;7.5 清空表
可以使用INSERT OVERWRITE通过插入空值来清除表(关闭动态分区覆盖)。
INSERT OVERWRITE test_p/*+ OPTIONS('dynamic-partition-overwrite'='false') */ SELECT * FROM test_p WHERE false;7.6 更新数据
目前,Paimon在Flink1.17及后续版本中支持使用UPDATE更新记录。只有主键表支持此功能,但不支持更新主键。MergeEngine需要deduplicate或partial-update才能支持此功能。 
UPDATE test SET item_id = 4, behavior = 'pv' WHERE user_id = 3;配置MergeEngine只需要with加上相关属性:'merge-engine'='deduplicate',默认为deduplicate。
7.7 删除数据
目前,Paimon 在Flink1.17及后续版本中支持使用DELETE删除记录。需要表有主键并且MergeEngine需要为deduplicate(默认deduplicate)
DELETE FROM test WHERE user_id = 3;7.8 Merge Into
通过merge into实现行级更新,只有主键表支持此功能。需要用到paimon-flink-action-1.2.0.jar,上传文件:
[root@gbasehd111 lib]# pwd
/opt/gbaseHD/flink/lib
[root@gbasehd111 lib]# ll |grep action
-rw-r--r--. 1 root root 11381 9月 8 15:05 paimon-flink-action-1.2.0.jar语法说明:
<FLINK_HOME>/bin/flink run \
/path/to/paimon-flink-action-1.2.0.jar \
merge-into \
--warehouse <warehouse-path> \
--database <database-name> \
--table <target-table> \
[--target-as <target-table-alias>] \
--source-table <source-table-name> \
[--source-sql <sql> ...]\
--on <merge-condition> \
--merge-actions <matched-upsert,matched-delete,not-matched-insert,not-matched-by-source-upsert,not-matched-by-source-delete> \
--matched-upsert-condition <matched-condition> \
--matched-upsert-set <upsert-changes> \
--matched-delete-condition <matched-condition> \
--not-matched-insert-condition <not-matched-condition> \
--not-matched-insert-values <insert-values> \
--not-matched-by-source-upsert-condition <not-matched-by-source-condition> \
--not-matched-by-source-upsert-set <not-matched-upsert-changes> \
--not-matched-by-source-delete-condition <not-matched-by-source-condition> \
[--catalog-conf <paimon-catalog-conf> [--catalog-conf <paimon-catalog-conf> ...]]
# 参数说明
--source-sql <sql> 可以传递sql来配置环境并在运行时创建源表。
"match"的说明:
1. matched:更改的行来自目标表,每个行都可以根据条件匹配源表行(source ∩ target):
合并条件(--on)
匹配条件(--matched-xxx-condition)
2. not-matched:更改的行来自源表,并且根据条件所有行都不能与任何目标表的行匹配(source – target):
合并条件(--on)
不匹配条件(--not-matched-xxx-condition):不能使用目标表的列来构造条件表达式。
3. not-matched-by-source:更改的行来自目标表,并且基于条件所有行都不能与任何源表的行匹配(target – source):
合并条件(--on)
源不匹配条件(--not-matched-by-source-xxx-condition):不能使用源表的列来构造条件表达式。案例实操:
CREATE TABLE ws1 (
id INT,
ts BIGINT,
vc INT,
PRIMARY KEY (id) NOT ENFORCED
);
INSERT INTO ws1 VALUES(1,1,1),(2,2,2),(3,3,3);
CREATE TABLE ws_t (
id INT,
ts BIGINT,
vc INT,
PRIMARY KEY (id) NOT ENFORCED
);
INSERT INTO ws_t VALUES(2,2,2),(3,3,3),(4,4,4),(5,5,5);- 案例一: ws_t与ws1匹配id,将ws_t中ts>2的vc改为10,ts<=2的删除
./bin/flink run ./lib/paimon-flink-action-1.2.0.jar \
merge_into \
--warehouse hdfs://node01:8020/paimon/fs/internal/warehouse \
--database default \
--table ws_t \
--source_table default.ws1 \
--on "ws1.id"="ws_t.id" \
--merge_actions matched-upsert,matched-delete \
--matched_upsert_condition "ws_t.ts>2" \
--matched_upsert_set "vc=10" \
--matched_delete_condition "ws_t.ts<=2"- 案例二: ws_t与ws1匹配id,匹配上的将ws_t中vc加10,ws1中没匹配上的插入ws_t中
./bin/flink run ./lib/paimon-flink-action-1.2.0.jar \
merge_into \
--warehouse hdfs://node01:8020/paimon/fs/internal/warehouse \
--database default \
--table ws_t \
--source_table default.ws1 \
--on "ws1.id"="ws_t.id" \
--merge_actions matched-upsert,not-matched-insert \
--matched_upsert_set "vc=ws_t.vc+10" \
--not_matched_insert_values "*"- 案例三: ws_t与ws1匹配id,ws_t中没匹配上的,ts大于4则vc加20,ts=4则删除
./bin/flink run ./lib/paimon-flink-action-1.2.0.jar \
merge_into \
--warehouse hdfs://node01:8020/paimon/fs/internal/warehouse \
--database default \
--table ws_t \
--source_table default.ws1 \
--on "ws1.id"="ws_t.id" \
--merge_actions not-matched-by-source-upsert,not-matched-by-source-delete \
--not_matched_by_source_upsert_condition "ws_t.ts>4" \
--not_matched_by_source_upsert_set "vc=ws_t.vc+20" \
--not_matched_by_source_delete_condition "ws_t.ts=4"- 案例四: 使用--source-sql创建新catalog下的源表,匹配ws_t的id,没匹配上的插入ws_t
./bin/flink run ./lib/paimon-flink-action-1.2.0.jar \
merge_into \
--warehouse hdfs://node01:8020/paimon/fs/internal/warehouse \
--database default \
--table ws_t \
--source_sql "CREATE CATALOG fs2 WITH ('type' = 'paimon','warehouse' = 'hdfs://node01:8020/paimon/fs2/internal/warehouse')" \
--source_sql "CREATE DATABASE IF NOT EXISTS fs2.test" \
--source_sql "CREATE TEMPORARY VIEW fs2.test.ws2 AS SELECT id+10 as id,ts,vc FROM ws_t" \
--source_table fs2.test.ws2 \
--on "ws_t.id = ws2.id" \
--merge_actions not-matched-insert \
--not_matched_insert_values "*"8. DQL查询表
Paimon的批量读取返回表快照中的所有数据。默认情况下,批量读取返回最新快照。
-- 设置执行模式为批模式
SET 'execution.runtime-mode' = 'batch';8.1 时间旅行
paimon按照日期保存了表的快照数据, 同时使用EARLIEST和LATEST标识最早的和当前的快照版本: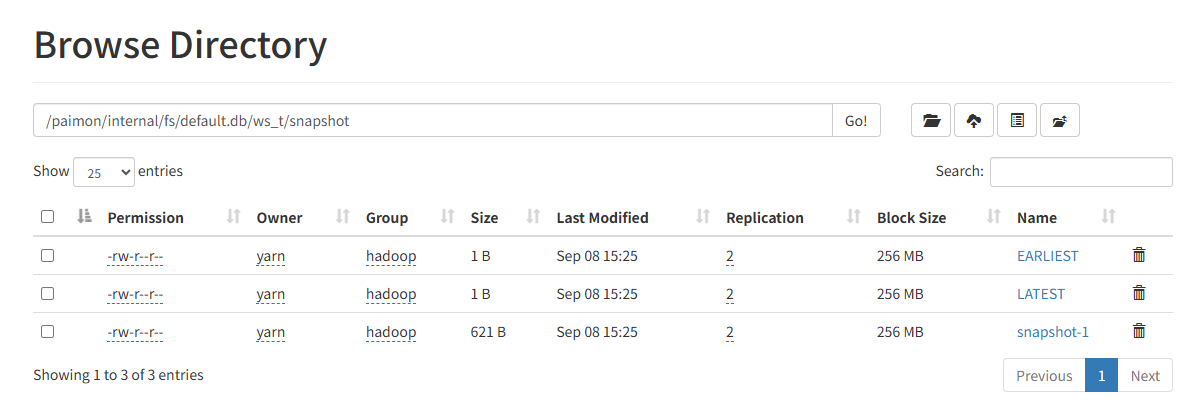
- 读取指定id的快照
Flink SQL> SELECT * FROM ws_t /*+ OPTIONS('scan.snapshot-id' = '1') */;
+----+----+----+
| id | ts | vc |
+----+----+----+
| 2 | 2 | 2 |
| 3 | 3 | 3 |
| 4 | 4 | 4 |
| 5 | 5 | 5 |
+----+----+----+
4 rows in set- 读取指定时间戳的快照
SELECT * FROM ws_t$snapshots;
SELECT * FROM ws_t /*+ OPTIONS('scan.timestamp-millis' = '1688369660841') */;8.2 增量查询
读取开始快照(不包括)和结束快照之间的增量更改。
-- “3,5”表示快照 3 和快照 5 之间的更改
Flink SQL> SELECT * FROM ws_t /*+ OPTIONS('incremental-between' = '3,5') */;
+----+----+----+
| id | ts | vc |
+----+----+----+
| 4 | 4 | 4 |
| 5 | 5 | 25 |
| 11 | 1 | 1 |
| 12 | 2 | 2 |
| 13 | 3 | 20 |
| 15 | 5 | 25 |
+----+----+----+
6 rows in set (1.75 seconds)在batch模式中,不返回DELETE记录,因此-D的记录将被删除。如果你想查看DELETE记录,可以查询audit_log表:
Flink SQL> SELECT * FROM ws_t$audit_log /*+ OPTIONS('incremental-between' = '3,5') */;
+---------+----+----+----+
| rowkind | id | ts | vc |
+---------+----+----+----+
| -D | 4 | 4 | 4 |
| +U | 5 | 5 | 25 |
| +I | 11 | 1 | 1 |
| +I | 12 | 2 | 2 |
| +I | 13 | 3 | 20 |
| +I | 15 | 5 | 25 |
+---------+----+----+----+
6 rows in set (1.22 seconds)8.3 流式查询
设置流模式读取数据:
SET 'execution.checkpointing.interval'='30s';
SET 'execution.runtime-mode' = 'streaming';设置从最新的地方开始读取,也就是当前没有新数据进来,在页面上不会显示数据:
SELECT * FROM ws_t /*+ OPTIONS('scan.mode' = 'latest') */- 时间旅行
-- 如果只想处理今天及以后的数据,则可以使用分区过滤器来实现
SELECT * FROM test_p WHERE dt > '2023-07-01'如果不是分区表那就需要使用时间旅行的流读取:
-- 从指定快照id开始读取变更数据
SELECT * FROM ws_t /*+ OPTIONS('scan.snapshot-id' = '1') */;
--从指定时间戳开始读取
SELECT * FROM ws_t /*+ OPTIONS('scan.timestamp-millis' = '1688369660841') */;
--第一次启动时读取指定快照数据,并继续读取变化
SELECT * FROM ws_t /*+ OPTIONS('scan.mode'='from-snapshot-full','scan.snapshot-id' = '3') */;需要注意的的是如果不是从首次位置开始读取的话,查询结果的变更记录是不准确的。 2. 使用ConsumerID 如果数据源是Kafka,在流式读取表时可以指定consumer-id,这样可以实现和Flink类似的savepoint的功能:
-- 指定consumer-id开始流式查询
SELECT * FROM ws_t /*+ OPTIONS('consumer-id' = 'atguigu') */;- 当之前的作业停止后,新启动的作业可以继续消耗之前的进度,而不需要从状态恢复。新的读取将从消费者文件中找到的下一个快照ID开始读取。
- 在判断一个快照是否过期时,Paimon会查看文件系统中该表的所有消费者,如果还有消费者依赖这个快照,那么这个快照就不会因为过期而被删除。
- 当没有水印定义时,Paimon表会将快照中的水印传递到下游Paimon表,这意味着您可以跟踪整个管道的水印进度。
9. 查询优化
建议在查询时指定分区和主键过滤器,这将加快查询数据的速度。Paimon会按主键对数据进行排序,从而加快点查询和范围查询的速度。使用复合主键时,查询过滤器最好形成主键的最左边前缀,以获得良好的加速效果。
-- 通过为主键最左边的前缀指定范围过滤器
SELECT * FROM orders WHERE catalog_id=1025 AND order_id=29495;
-- 下面例子的过滤器不能很好地加速查询:
-- order_id不是主键
SELECT * FROM orders WHERE order_id=29495;
-- order_id不是主键,OR会让加速失效
SELECT * FROM orders WHERE catalog_id=1025 OR order_id=29495;10. 系统表
系统表保存了每个表的元数据和信息,可以通过批量模式查询系统表。
10.1 快照表(Snapshots Table)
通过查询快照表,可以了解该表的提交和过期信息以及数据的时间旅行。
SELECT * FROM ws_t$snapshots;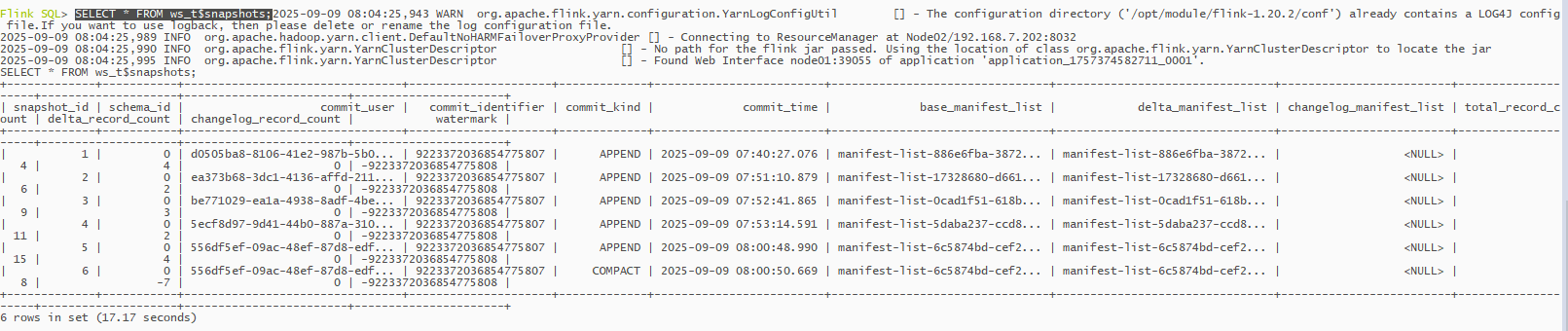
10.2 模式表(Schemas Table)
通过schemas表可以查询该表的历史schema
SELECT * FROM ws_t$schemas; 可以连接快照表和模式表以获取给定快照的字段:
可以连接快照表和模式表以获取给定快照的字段:
SELECT s.snapshot_id, t.schema_id, t.fields
FROM ws_t$snapshots s JOIN ws_t$schemas t
ON s.schema_id=t.schema_id where s.snapshot_id=3;10.3 选项表(Options Table)
可以通过选项表查询DDL中指定的表的选项信息。未显示的选项将是默认值。
Flink SQL> SELECT * FROM ws_t$options;
Empty set (8.94 seconds)10.4 审计日志表(Audit log Table)
如果需要审计表的changelog,可以使用audit_log系统表。通过audit_log表,获取表增量数据时可以获取rowkind列。您可以利用该栏目进行过滤等操作来完成审核。 rowkind 有四个值:
- +I:插入操作。
- -U:使用更新行的先前内容进行更新操作。
- +U:使用更新行的新内容进行更新操作。
- -D:删除操作。
SELECT * FROM ws_t$audit_log;10.5 文件表(Files Table)
可以查询特定快照表的文件。
-- 查询最新快照的文件
SELECT * FROM ws_t$files;
-- 查询指定快照的文件
SELECT * FROM ws_t$files /*+ OPTIONS('scan.snapshot-id'='1') */;10.6 标签表(Tags Table)
通过tags表可以查询表的标签历史信息,包括基于哪些快照进行标签以及快照的一些历史信息。您还可以通过名称获取所有标签名称和时间旅行到特定标签的数据。
SELECT * FROM ws_t$tags;11. 维表Join
Paimon支持Lookup Join语法,它用于从Paimon查询的数据来补充维度字段。要求一个表具有处理时间属性,而另一个表由查找源连接器支持。
11.1 数据准备
CREATE TABLE customers (
id INT PRIMARY KEY NOT ENFORCED,
name STRING,
country STRING,
zip STRING
);
INSERT INTO customers VALUES(1,'zs','ch','123'),(2,'ls','ch','456'), (3,'ww','ch','789');
CREATE TEMPORARY TABLE Orders (
order_id INT,
total INT,
customer_id INT,
proc_time AS PROCTIME()
) WITH (
'connector' = 'datagen',
'rows-per-second'='1',
'fields.order_id.kind'='sequence',
'fields.order_id.start'='1',
'fields.order_id.end'='1000000',
'fields.total.kind'='random',
'fields.total.min'='1',
'fields.total.max'='1000',
'fields.customer_id.kind'='random',
'fields.customer_id.min'='1',
'fields.customer_id.max'='3'
);11.2 使用Join
SELECT o.order_id, o.total, c.country, c.zip
FROM Orders AS o
JOIN customers
FOR SYSTEM_TIME AS OF o.proc_time AS c
ON o.customer_id = c.id;Lookup Join算子会在本地维护一个RocksDB缓存并实时拉取表的最新更新。查找连接运算符只会提取必要的数据,因此您的过滤条件对于性能非常重要。 如果Orders(主表)的记录Join缺失,因为customers(查找表)对应的数据还没有准备好。可以考虑使用Flink的Delayed Retry Strategy For Lookup。